Who we are
We are the developers of
Plastic SCM, a full version control stack (not a Git variant). We work on the strongest branching and merging you can
find, and a core that doesn't cringe with huge binaries and repos. We also develop the GUIs, mergetools and everything needed to give you the full version control stack.
If you want to give it a try, download it from
here.
We also code
SemanticMerge, and the
gmaster Git client.
Active Directory - Work with huge AD trees
Recently we have experienced an issue when configuring the system authentication mode to Active Directory. The Active Directory tree contained more than 3000 entries.
By default, Active Directory allows fetching only 1000 entries foreach search request to the Active Directory Domain. The main reasons of this limit are security and performance.
If a search query to the Active Directory returns more than 1000 results, the ActiveDirectory throws an exception (sizelimitexception, LDAP error code 4).
Plastic SCM catches the exception and shows the following warning message:
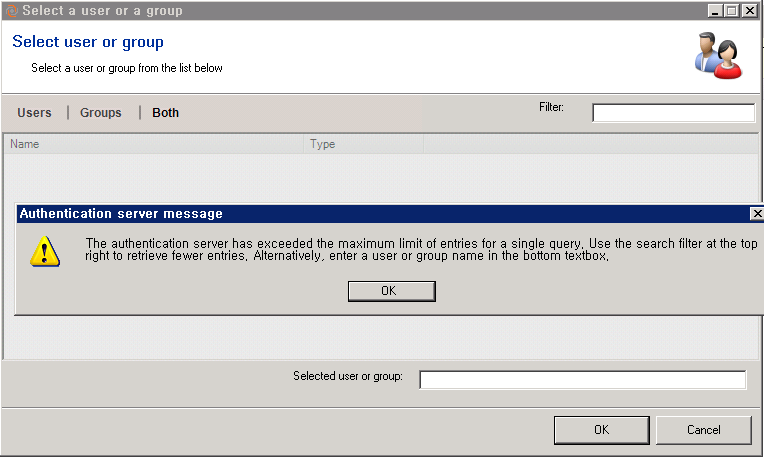
At this point, there are three possible solutions to get a result:
- Close the warning message and specify a filter on the "Filter" textbox from the User Selection dialog.
Doing this, Plastic SCM will filter the query to the Active Directory domain, and will retrieve less results than before.
Constraints:
- The specified filter has to return less than 1000 results.
- Specify a subdomain to the PlasticSCM server configuration instead of the entire Active Directory domain.
Doing this, Plastic SCM server will query only for users and groups from the specified subdomain.
Example:
If you currently have configured your PlasticSCM server ActiveDirectory's domain to:
"mycompany.com" (or "dc=mycompany,dc=com")
Change it to:
"developers.mycompany.com" (or "dc=developers,dc=mycompany,dc=com")
You can perform this change through the server configuration wizard.

Constraints:
- All the PlasticSCM users must be contained on that subdomain
- The list of users/group on the subdomain contains less than 1000 entries.
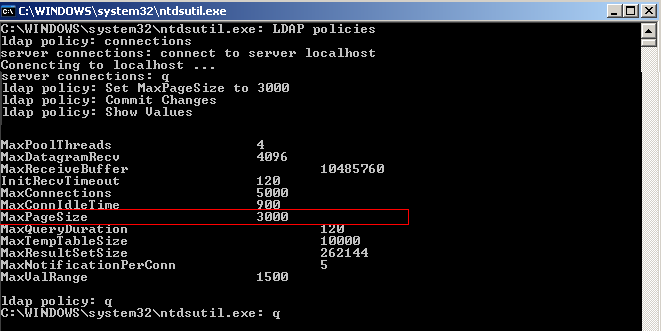
- Change the Active Directory's limit. You can do that by following this guide from Microsoft's Knowledge base: http://support.microsoft.com/kb/315071
(Sections: "Starting Ntdsutil.exe", "Viewing current policy settings" and "Modifying policy settings").
Mainly, the steps are the following:
- Run "Ntdsutil.exe" on the Active Directory machine.
- At the "Ntdsutil.exe" command prompt, type "LDAP policies"
- At the "LDAP policy" command prompt, type "connections"
- At the "server connection" command prompt, type "connect to server MYHOST.mydomain.com"
Examples:
"connect to server localhost"
"connect to server ldapserver.archgroup.com" - At the "server connection" command prompt, type "q"
- At the "LDAP policy" command prompt, type "Set MaxPageSize to NEW_VALUE"
Example:"Set MaxPageSize to 3000"
- At the "LDAP policy" command prompt, type "Commit Changes"
- At the "LDAP policy" command prompt, type "q"
- At the "Ntdsutil.exe" command prompt,type "q"
Jesús González
I joined the Plastic team as a junior eons ago and I worked on almost every area since then. From importers to the latest Unity plugin, security to GitSync...
I play soccer, like cars, love telling near to true stories and I'm also learning to play electric guitar.
You can reach me at
@ilovemerge.
Who we are
We are the developers of
Plastic SCM, a full version control stack (not a Git variant). We work on the strongest branching and merging you can
find, and a core that doesn't cringe with huge binaries and repos. We also develop the GUIs, mergetools and everything needed to give you the full version control stack.
If you want to give it a try, download it from
here.
We also code
SemanticMerge, and the
gmaster Git client.
Move detection – advanced bits
Move detection is one of the big features in 4.0, as I’m sure you’re already aware of.
It has been implemented on top of the same underlying technology we use for Xdiff and Xmerge.
The point is: you just move a file on your workspace without issuing a “cm mv” operation (command line, GUI or through a plugin), and later Plastic is able to “detect” the move happened.
How it works
The principles of move detection are quite easy: Plastic has a list of the files (stored under .plastic/plastic.wktree file on the workspace) that are “controlled” under the workspace. Then you decide to look for changes:
If a file on the workspace is not on the list: then it is proposed as an “added” candidate
If a file is on the list but not on the workspace: then it is proposed as a “deleted” candidate
How the “moves” are detected? The “added candidates” are matched with the “deleted candidates” and if they’re “similar enough” then they’re proposed as “moved”.
Let’s make it more complicated
What if foo.c is something like the following?
And we rename it to bar.c and modify it this way:
The file was so small that this little change will make the two versions less than 90% different, so “pending changes” view will look like this:
As you can see plastic detects a “potential add” and a “potential delete”.
Matching manually
Right click on the “potentially added” file and select “search matches”:
And then the “matching” dialog will show up. You can slide the similarity bar until the candidate appears:
And once you “accept the selected match”, the “pending changes view” will reflect the move:
Pablo Santos
I'm the CTO and Founder at Códice.
I've been leading Plastic SCM since 2005. My passion is helping teams work better through version control.
I had the opportunity to see teams from many different industries at work while I helped them improving their version control practices.
I really enjoy teaching (I've been a University professor for 6+ years) and sharing my experience in talks and articles.
And I love simple code.
You can reach me at
@psluaces.
Who we are
We are the developers of
Plastic SCM, a full version control stack (not a Git variant). We work on the strongest branching and merging you can
find, and a core that doesn't cringe with huge binaries and repos. We also develop the GUIs, mergetools and everything needed to give you the full version control stack.
If you want to give it a try, download it from
here.
We also code
SemanticMerge, and the
gmaster Git client.
plastic 700 sec – git 1200 sec – a c# development story
The short story: take a code tree of 192.818 files in 33.877 directories (overall size: 5.75GB) and check in on your favorite version control tool. Plastic SCM needs 713 secs, Git needs 1287 secs.
Yes, we’re faster than Git!!!!!!
And yes: a C# program can outperform a well-written C program by a 44%!!!
(Ok, we’d be running cycles around “gitty” had we chosen C++ :P)
Pablo Santos
I'm the CTO and Founder at Códice.
I've been leading Plastic SCM since 2005. My passion is helping teams work better through version control.
I had the opportunity to see teams from many different industries at work while I helped them improving their version control practices.
I really enjoy teaching (I've been a University professor for 6+ years) and sharing my experience in talks and articles.
And I love simple code.
You can reach me at
@psluaces.
Who we are
We are the developers of
Plastic SCM, a full version control stack (not a Git variant). We work on the strongest branching and merging you can
find, and a core that doesn't cringe with huge binaries and repos. We also develop the GUIs, mergetools and everything needed to give you the full version control stack.
If you want to give it a try, download it from
here.
We also code
SemanticMerge, and the
gmaster Git client.
How to link repositories using Xlinks
Xlinks are one of the coolest new features in Plastic SCM 4.0.
They're basically a way to link different "trees" together so that a "project" repository can have "versioned links" to other component repositories and then just switching to a branch on the "project" repo will set up all the code for you.
For 3.0 users: instead of delving with complex multi-repository selectors, Xlinks enable a way to just link to repos and download them easily (developers on your team won't have to copy/paste complex selectors, just switch to the right branches).
For Git users: Xlinks are "submodules" done right!
I’m going to show you how easy is working with multiple repositories at the same time using Xlinks.
We have several repositories, one for the source code, one for marketing stuff and the last one for third party tools.
Core
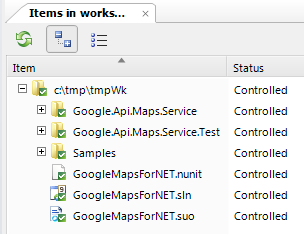
ThirdParty

Marketing
Motivation
It’s a good idea to have your information divided into isolated repositories since they are independent sub-projects, but actually they are part of the same project, so many times they will need to evolve together and share their content. For example, the Core repository needs the ThirdParty repository to achieve a successful build.
How can we mix these repositories and work with all of them at the same time? Xlinks.
Solution
We have to create a new repository that will be the one who is going to manage the Xlinks to external repositories. This will be our “Project” repository.
Create a new workspace working against the new repository, make three new directories, this will be the skeleton for the final structure.

Now we create the Xlinks to our external repositories. You can find more info about how to create them issuing “cm xlink --help” but basically you just need to type ‘--w’ if you want to create a writable Xlink, where is going to be placed the external repository content, the external repository path that is going to be mounted and finally the starting changeset of the external repository.
Sub-root paths will be supported in the future but from now you can only use the root path “/”.
Now checkin ‘em all!!! You can use the pending changes view to do it.

When everything is inside the repository your Items view will be like image below, notice the small arrows over the icon means that they are Xlinks to external repositories.

The last step to finally get the external content is perform an update operation, you can do it by right clicking on the workspace root item and Update.
One repository to rule them all, One repository to find them.
One repository to bring them all and in the darkness bind them.
Extra bonus
Do you remember that we created the Xlink with the “--w”? That means that they are writable! You can modify items under an Xlink, remove, move, merge, create branches, basically EVERYTHING.
With writable Xlinks you can evolve the 4 repositories at the same time, try to create a new branch on your Project repository, switch to it. Checkout a file inside an external repository, modify it a little bit and finally checkin it. PlasticSCM will automatically create a new branch on the remote repository to keep the change done! And you don’t have to care about nothing it simply works!
Manuel Lucio
I'm in charge of the Customer Support area.
I deal with complex setups, policies and working methodologies on a daily basis.
Prior to taking full responsibility of support, I worked as software engineer. I have been in charge of load testing for quite some time, so if you want to know how well Plastic compares to SVN or P4 under a really heavy load, I'm your guy.
I like to play with Arduino GPS devices, mountain biking and playing tennis.
You can find me hooked to my iPhone, skate-boarding or learning Korean... and also here
@mrcatacroquer.




















2 comentarios: