Distributed development for Windows programmers
Each time someone starts writing on distributed development there are some arcane and obscure commands that immediately show up to specify how the changes have to be popped from or pushed to some freely available internet repository. And that's fine, but most of the developers out there are more used to right menus, dialogs and options than typing on black consoles. So at the end it looks like distributed development is something for open source developers working on Linux, and that's obviously not true.
Let's try to describe the whole picture and how you, as a Windows developer most likely working on a commercial project for your company, can also benefit for the new trend of going distributed.
Your current scenario
So, you're using Visual Studio on a daily basis and committing changes to your version control, getting updates from the rest of the team and potentially creating tons of small feature branches to better isolate your code changes (if you didn't embrace yet branching then I bet it will be a great first step before going distributed, but keep reading to check how it will also benefit you).
 You probably have several workspaces to work on different projects or just to focus on different tasks without having to update the whole thing again and again (which should be also fast, but you know…).
You probably have several workspaces to work on different projects or just to focus on different tasks without having to update the whole thing again and again (which should be also fast, but you know…).
 So basically you go to one of your working copies, make changes from there, and submit there to your central server at the office which lets you forget about how or where the data is stored and it is powerful enough to run very fast and make your life easy :-P.
So basically you go to one of your working copies, make changes from there, and submit there to your central server at the office which lets you forget about how or where the data is stored and it is powerful enough to run very fast and make your life easy :-P.
What this distributed thing is all about?
It's much simpler than you think. Let's start with a nice scenario: suppose you've decided to work at home for a week, avoiding the daily traffic jam and having some spare time at noon to do a break and practice some sports close to your place, sounds good? (Later I'll describe another not so beautiful scenario).
The situation will be something like the following picture, where you've access to your version control server only through a VPN or network connection.

The main issues you'll face will be:
Connection can be lost, slowing you down, having to reconnect and simply making you lose time.Connection can be slow: switching to a different branch or simply committing or retrieving changes will be painfully slow.What's the solution? Going distributed. Imagine you've your own version control server on your laptop, so you don't have to connect to the office's central server anymore, everything will be extremely fast, no waits, no connections being lost! Of course, since your laptop won't be as powerful as the central server, you don't need a full copy of all the repositories but only certain parts of the ones you'll need to work with, so you can keep making changes and then synchronize them back with the central server when you're back at the office or through the network when you decide to send them back.

The advantages are clear:
You can move your laptop from work to home (or whatever different locations you can think of) and you'll always be able to continue working seamlessly.You won't have to wait for changes to be downloaded to your machine from distant locations through slow and unreliable networks.You're free to continue making changes having full version control support (hey! You can try a poor's man approach just copying a workspace to your laptop, but then you won't be able to access file history, switch branches, make intermediate commits and all this things you get used to when you have version control).Alternative scenarios
As a professional developer there are many scenarios where you can benefit from distributed development. The one described above, working at home, is just one of them but there are many other chances like:
Working on the customer's site for some days (or even much longer) and still being able to do controlled changes to the source code.Attend a demo, event and so on and still be able to try a nice change on the code but doing so in a controlled way.The multi-site scenario: connecting several teams by using distributed development between their servers.Hands on lab: what to do next
Once the theory is clear, let's just make it happen. Here're the steps we're going to follow:
Set up a server on your laptop.Import the repositories you need from the central server.Start working on your distributed server at your laptop.Submit your changes back to the central server.Get changes from the central server.Set up your own "server"
Depending on the version control system you're using it will require different steps. Let me clarify:
If you're using an open source system like Git you won't have a server as such, it will just be a local copy on a directory (typically your workspace) so set up is fast and easy. You can download the Windows installer from here: http://code.google.com/p/msysgit.If you plan to use Mercurial you can find the download here: http://mercurial.selenic.com/downloads. Mercurial includes a small HTTP server that allows you to synchronize with other servers and other people to take changes from you.If you plan to use Plastic SCM you can set up the client and server on your machine in less than 45 seconds as you can see in this video: http://www.youtube.com/watch?v=CVlsVtxZUkk. Plastic is meant to be used from a graphical user interface from day one, so it will be pretty straightforward to use (you know I'm obviously biased here, but just check it and judge it yourself).Unfortunately for Windows developers out there, Team Foundation Server is out of the picture since it simply does not support the distributed workflow. Although it can be installed in less than 45 minutes :-P.Your server (whether is a real one or just a directory with a copy like in Git) will hold your replicated data and will let you work with your code while you're disconnected.
Replicate from the central server
Once you've your server set up you need to perform an initial code import from the central server. To make things simpler suppose you're only going to work on a single project while disconnected from the central location. Then you'd have to replicate (or clone depending on your specific SCM jargon) one single repository into your laptop.
Normally you won't replicate the entire repository but only part of it. What does it mean? Your central repo will contain hundreds if not thousands of feature branches, releases and so on, but it will be enough for you to work distributed if you get the main or master branch into your cloned repo.

You can have a very big central repo with many branches like the one on the previous picture but you only need the main one to start working.
So the clone process will just mean replicating the remote main branch into a new local repository on your laptop.
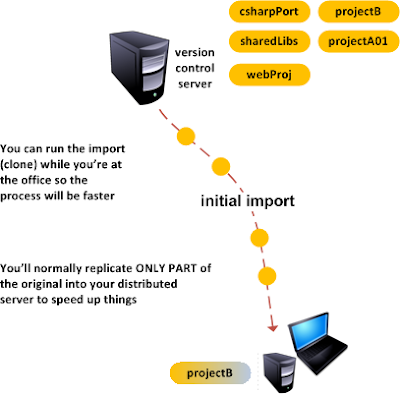
You can do that with Git using the git clone command, or you can do that with Plastic even within Visual Studio as you can see on the following picture.

You can see how I've specified centralserver as the replication source and then a new repository I've just created on my laptop as destination. I click on replicate and the import process starts, as you can see on the following screenshot. (Remember I'm driving the whole process from within Visual Studio 2010).

The initial clone can take a little longer depending on the size of your repos (and the speed of your connection, so it's better if you do it while you're on the same network!), but the good thing is after that all the following operations will be extremely fast.
And once you're done replicating you can browse the changes on your new repository, which will contain all the commits (or changesets depending on your SCM) and labels (tags) coming from the central server.

The version control will keep track of which is the source of each element being replicated. For instance, in the previous screenshot you can see how the selected commit is coming from the remote repository you've just replicated (check the properties tag).
Start working on your laptop disconnected from the central server
You've already completed your initial clone, so it's time to start working on your code without having to be slowed down but your central server.
The pattern I'm going to recommend is using feature branches (or the good-ol branch per task branching pattern as you can find here: http://www.cmcrossroads.com/bradapp/acme/branching).
What does it mean? Well, for every bugfix or new feature you're going to implement you'll create a brand new branch, make your changes there and get them integrated into your main branch (or master or trunk depending on your jargon) later.
It's much, much easier than what you might think. Just google for
feature branches if you need more information on the subject, but it's really simple as you'll see.
Creating a new branch is an easy task on any modern version control tool. I'm showing how to do it with Plastic SCM and Visual Studio: I'm going to create a branch from a given changeset as you can see on the following screenshot. I just right click on the changeset and select create branch from this changeset. Different SCMs will do it on a different way but as soon as they're ready for branching (which is unfortunately not true for all of them), it won't be hard to do.

With Plastic SCM you'll find a dialog like the following where you can specify some extra data about the branch to create like comments, name and so on.

Since I'm just going to fix a bug on the new branch I give it a meaningful name. Note: it's very important to follow some sort of naming convention for feature branches since you're going to deal with a big number of them. My favorite is giving them a certain prefix and then a number, which is directly taken from the associated issue on the bug/issue tracking system.
After the branch has been created your situation will be something like the following:

So next step is just switch your workspace to the branch and start working on it. What does it mean? Well, tell your SCM that the changes you're going to make to fix the code have to go to the branch you've just created. It's not a big deal either!

Now it's the time of doing some real coding, making changes on your code to fix a given bug or issue. Not hard to do using Visual Studio 2010 (ok, or extremely hard depending on the specific bug!).

Visual Studio (from long time ago) comes with the pending checkins perspective to communicate with your version control and find what you've changed. In my example I've just modified a single file and I'm ready to commit it (and even added a meaningful comment to the change).
If you go back to inspecting your repository after your initial commit you'll see something like the following:

A couple of interesting things: first there's a new changeset on your branch and your changeset is not replicated (look at the replication source property on the right).
You can do very useful things like inspect the changes you've just made which is one of the good reasons of having your own version control on your laptop!

You can now easily repeat the process to work on different bug fixes, all starting from a well-known point, creating a branch for each of them.
Send your changes to the central server
You've been working for a while and you've already fixed a couple of bugs, so it's time to send your changes back to the central server. Hook up to your VPN and then push your changes.
In order to do so: the sequence of steps will vary depending on the SCM of choice. In case you're using Plastic SCM you can do it from the branch explorer within Visual Studio, simply select the branch you want to push, right click on it and say "push".

And you're done! Repeat the process for every branch you want to submit.
Getting remote changes
Getting remote changesets from the central server is also pretty straightforward. You'll have to repeat the steps you've completed when setting up your repository but this time instead of getting the entire branch it will only find what's have been modified since the last clone! Faster and easier.
Wrapping up
It's been a pretty fast step by step tutorial but I think I've covered the major concepts involved in replication and even some examples on how to achieve it with a specific tool, all within your beloved Visual Studio and without typing a single command!
Pablo Santos
I'm the CTO and Founder at Códice.
I've been leading Plastic SCM since 2005. My passion is helping teams work better through version control.
I had the opportunity to see teams from many different industries at work while I helped them improving their version control practices.
I really enjoy teaching (I've been a University professor for 6+ years) and sharing my experience in talks and articles.
And I love simple code.
You can reach me at
@psluaces.






















10 comentarios: