Branch per task workflow explained
My goal is to explain how the branch per task pattern (a.k.a. issue branches, task branches, feature branches and even bug branches) works and why is so good to keep projects under control.
Branching and merging is a key topic nowadays, specially due to the raise of DVCS, so I expect you find this post on branch and merge strategies worth. :)
I'll try to cover also the relationship between this pattern and agile methodologies like Scrum.
I'll also highlight why branch per task is the core of parallel development and why it is much better than serialized development or trunk development.
What is a task
Let me ask you a question first: are you using an issue tracking system? If the answer is yes, then skip this section and jump to the next. If not keep reading!
So, you do not have an issue tracking system in place!!! Let's get this fixed first. Go and grab one. No, don't start a long and boring evaluation, just go and grab one, any system is better than not using one. In fact, read Joel's test: 12 steps to better code and triple check point 4.
There are many systems out there you can use:
- Free ones: Bugzilla, Mantis, Trac.
- Commercial: Jira, OnTime, Rally, VersionOne
And many more! The issue tracking systems are meant to track issues (bugs) but do not limit yourself to only bugs. Rule of thumb - everything is a new task: every change you do in your code will have an associated task (or issue). Yes, it can sound extreme if you're not yet doing that, but please consider it: never do a change in your code again without having an associated task. It doesn't matter whether you're fixing a bug or aligning a button or implementing a brand new feature: create a task for them! Note: do not embrace a project management nightmare trying to force developers to make a huge effort to keep the issue tracking system updated. They simply won't do it, or it will take much more time than what is worth. Keep it simple. Note (again): developers must understand issue tracking as a core team practice, as something that helps them, on a daily basis, to keep track of what they've been doing. If they perceive it just as a management control mechanism it will turn out to be much less useful than what it should.
Tasks must be short!
Tasks are meant to be short and bug fixes too. So, do not introduce a task that's supposed to take 3 weeks to be completed. Split it into shorter ones. If you're used to agile methods like SCRUM you'll remember the key rule is trying to keep tasks under 16 hours. I think it is a very good remark.
The task workflow
The next figure shows how the task workflow works, and its relationship with the entire scrum process. The tasks I refer to are the ones you use when you decompose the user stories during sprint planning. (Click to enlarge!)

Version control sits on the center of the graphic as coordinator of the entire picture, but let's see what the main components are:
Task
What is about? everything will be a task, and tasks, as described in the previous topic, are managed by your favorite issue tracking system. More importantly, tasks come from the product backlog (or whatever list of tasks, WBS, you use). How uses it? everyone. A developer can enter a task, a project manager too; testers can introduce bugs, defects and so on. The task is the central point for project coordination.
Branch
What is about? It is the core of the developer's work. Developers will always work on branches, never on the main branch (or trunk). Every task will always start from a well-known point, a baseline or stable release (which closes the cycle). Who uses it? Developers on their daily work. Integrators when they need to create releases. Every task is tested and validated before marking it as "resolved" on your issue tracking system.
Integration
What is about? Once a number of tasks are finished, it's time to create a new release. Remember that "release early, release often" is a best practice worth following to avoid big bang integration (the root of all evil in the SCM world). Who uses it? The integrators.
Integrators can be developers playing the role once a week, once a day (depending on the release creation frequency). The integrator role can be a full time job on big projects. They not only merge the branches back to main, but are responsible of getting the build done right. So probably they'll take a quick look at the code, they'll ask the developers if something is not clear or if conflicts arise.
Responsibility is the key word behind the role of the integrator.
Release
What is it? The integration result is a new stable release. Stable means it passes the entire test suite, so no known errors are left (or they're well-known). Who uses it? The entire team. Once a release is finished, it can be passed to the testing group (if it does exist). Developers will use the newly created release as the starting point of the new tasks they'll work on during the next working cycle.
Frequently asked questions
FAQ: What's a task branch exactly?
ANSWER: You've probably heard of concepts like bug branches, topic branches and so on, didn't you? Ok, even if you didn't, here's the answer: is a branch you use to implement a given task. It's short-lived and its purpose is to be used only to implement a given feature or bugfix.
FAQ: But, weren't branches supposed to be evil?
ANSWER: Who told you that? I bet you found that on some Subversion guide, forum or manual, maybe even at some other SCM website, didn't you? Branches are excellent tools for developers, but they're not correctly handled by most of the version control systems out there, including CVS, Subversion, SourceSafe, Perforce, Team Foundation Server and many others. That's why they say branching is not good. It's not true, branching is great and you should use it on a daily basis, but you need the right tool for that.
It's not about DVCS
DVCS, distributed version control, is the buzzword on all programmers' forums these days. Git and Mercurial greatly contributed to get tons of developers interested on DVCS, and what's even more important: on branching and merging.
Branch per task is the core workflow used by most of the DVCS practitioners (including Plastic SCM) but the reason doesn't have to do with the fact that these systems can work on a distributed way but actually their ability to handle branching and especially merging correctly. The facts are clear: good DVCS systems are good doing branching and merging, but branch per task is not about distributed, it could be implemented on a centralized system too, provided good support for branching and merging is in place, which is normally not the case since the most common centralized systems like Subversion, CVS, TFS, Perforce and so on, can't handle branching correctly.
Why branch per task is better?
I've described in detail the branch per task pattern and I also talked about the task cycle and its main elements, so you've already concluded why branch per task is a good practice. My intention now is to highlight, in a detailed way, why branch per task is the best way of working for almost all the teams and almost all the time (there will be circumstances where you won't need to branch that often, but believe me it won't be so common).
Colliding worlds: serial vs parallel development
Let's take a look at a typical project following the serial development pattern, better known as trunk development or mainline development. It just means that there's a single branch where everyone check-ins his changes. It is very easy to set up and very easy to understand and it's the way most developers are used to work with tools like Subversion, CVS, SourceSafe and so on.
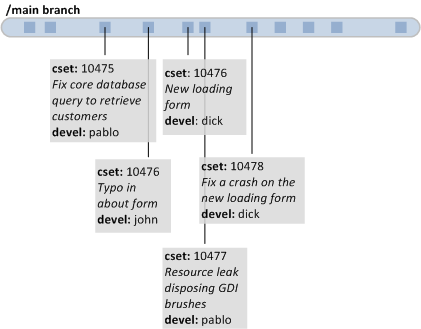
As you can see in the figure, the project evolves through check-ins made on the single branch (the trunk or main branch).
Every developer check-ins his changes there and since it's the central point of collaboration for everyone, developers have to be very careful to avoid breaking the build, which means doing a check-in which doesn't build correctly. In the example figure we see how dick creates a new loading form but makes a mistake (cset:10476) and then has to fix it in a later check-in (cset:10478).
It means the build has been broken between 10476 and 10478. Every developer updating his workspace in between would have been hit by the bug, and it most likely happened to pablo after he checked-in cset:10477 and updated his workspace accordingly.
Also, if you look carefully, you'll see we're mixing together important changes like the one made on cset:10475 (big change on one of the core queries, which could potentially break the application in weird ways) with safer ones like the typo fixed in cset:10476. What does it mean? It means that if we had to release right now the baseline could not be ready or not stable enough. Let's check how the same scenario would look like using parallel development:

As you can see there are several branches involved since every task is now a branch, and there are also merge arrows (the green lines) and baselines (we could have created baselines before, but using a branching pattern it is even clearer when to create them).
Using this example as basis, I'll start going through the problems we can find in serial development and how to get then fixed with parallel (task per branch) and why the entire model is better.
Code is always under control
How often do you check-in when you're working on trunk (mainline development)? I bet you're very careful before checking-in because you don't want your colleagues to come to your desk shouting the code is not building anymore, aren't you? So, when you're working on a difficult task, something hard to change that will take a few days to complete: where's your code? Is it under source control?
Most likely it won't be since you won't check-in things that doesn't compile, are not complete or simply collide with other changes. This is a big issue and something pretty normal with mainline: changes are outside of version control for a long time, until developers are done.
The version control is used just as a delivery mechanism instead of a real VCS. With branch per task you won't have this problem: you can check-in as often as you want to, even creating checkpoints frequently just to make sure you've your own development under control. Side bar - but it was working 5 minutes ago!! This must have happened to you too: you're working on a change, your code is working, then you change something and it doesn't work again and you lose time trying to figure out (normally commenting and uncommenting code here and there) what you did wrong. It is very usual when you're experimenting changes, learning an API or doing some difficult stuff. If you've your own branch: why don't you check-in after each change? Then you don't have to rely again on commenting code in and out for the test.
Keep the main branch pristine
Breaking the build is something very common using mainline development. You check-in some code that you didn't test properly, and you'll be breaking some tests or even worse: introducing code that doesn't compile anymore.
Keeping the main branch pristine is one of the goals of branch per task: you specifically control everything that enters the main branch, so there's no simple way to break the build. Also keep in mind the usage of the main branch is totally different with branch per task: instead of being the single rendezvous point for the entire team, where everyone gets synchronized continuously and instability can happen, the main branch is now a stable point, with well-known baselines.
Have well-known starting points - do not shoot moving targets!
Something that often happens when you're working on mainline mode is that it's not easy to describe which one is the exact starting point of your working copy. Let me elaborate it a little bit more:
You update your workspace to /main at a certain point in time as you can see in the following picture. What's that point? That point is not BL130 because there are a few changes after that so, if you find an error: is because of the previous changes or just due to the ones you just introduced?

You can easily say: well, if you're using continuous integration you'll try to ensure the build is always ok (although that's a pretty reactive technique where you first break the build and later fix it), so whatever you download will be ok. Yes, you're right but, still, what is this configuration? If you update there you'll be working with an intermediate configuration, something that's not
really well-known… you'll be shooting a moving target! Take a look know at how the situation looks like using branch per task:

As you can see there's a big difference: all your tasks start from a well-known point. There's no more guessing, no more "unstable configurations". Every task (branch) has a clear starting point, a well-known stable one. It really helps you staying focused on your own changes.
Enforce baseline creation
Creating baselines is a best practice. Using branch per task baselines become a central piece on your daily work. There's no better way to enforce a best practice than making it a central piece of your workflow.
Task independence
Every task starts from a well-known starting point: a baseline. So, tasks are not dependent on each other unless they really have to. This simple fact gives you huge flexibility.
Let's take a look at the following figure, as you can see is the same example we used above, but I annotated it with some circles and arrows. What do they mean? Every task is linked to the previous one but not due to a functional requirement but simply due to the check-in order. Why they're linked? Because on every check-in, if you modified some of the files that were previously modified before, you'll be merging
changes from different tasks together, and even if you didn't modify the same set of files, you'll be testing the changes together, creating a soft dependency between them. It simply doesn't happen when you've task branches. It is also important to note that using task branches the entire release process is stronger since you choose what goes into the next release (selecting which branches to merge) instead of just taking what's on the mainline.

Branches as unit of change
Let's take a look back and deep into the history of SCM: at the beginning there weren't changesets, all work was handled on a per-file basis. There wasn't a good way to know which changes (check-ins) where related to which tasks other than keeping a list of the files into the issue tracking, setting labels (an overkill!) or writing the changes down somewhere. Then changesets entered the picture and life got better: know you can relate change 10475 to core fix in database query. Often the issue trackers will keep a pointer to the changeset or vice versa. The problem is that it forces developers to use changesets as units of change, and that's not a very good idea. Let me explain you why: by definition a changeset can only contain one revision of one given file or directory so, what if you need to do more than one check-in to the same file while working on your task? You can't. So you'll end up checking-in less often than what's safe. Wrong! And then a new generation of SCMs entered the scene and they were able to handle branching and merging correctly. That's why now, with Plastic, it is possible to use branches as the real units of change. And branches are not restricted to the number of revisions you create for a certain file or directory. You're welcome to commit often and frequently!
Stop bug spreading
People dealing with dangerous materials work on controlled environments, and usually behind closed doors, in order to prevent catastrophes from spreading if they ever happen. We can learn a valuable lesson from them. Look at the following mainline example: Dick creates a bug, and immediately everyone hitting the main branch will be affected by it. There's no contention, there's no prevention and the actions are entirely reactive: you break the code and then you fix it, but the code got broken first.

Then, let's take a look at the same situation with branch per task. The bug will be there too, but we've a chance to react before it ever hits the mainline. There's contention and there's a preventive strategy in place.

Improved traceability
Easier done than said: look at branch task115. Do you know which is the related task on your preferred issue tracking system? I guess 115, right? Cool. Linked. Full CMMi-level traceability achieved. It can't be easier. After that we can implement cool integrations (and we often do with Plastic) to let you double click on a branch and check the related task or go to the task and check the modified files, create code reviews and so on. But the basic, core, key traceability is just kept by a really simple naming convention. You can't do this with changeset-based approaches or using mainline development.
Wrapping up!
It's been a long post! I hope I've shared all the ideas I have regarding the task workflow and how to get it implemented with versioning systems with powerful enough branching and merging.
We've used the pattern internally for years with very good results. Of course we do combine more than one pattern together: branch per task is used for short-term (tactical) purposes while the long term activities like bug fix releases, new maintenance code lines and so on are kept in longer (strategical) branches. Check this previous article for integration strategies.


You should really uppercase 'dick':
ReplyDelete"dick introduces a bug" turns out a bit ugly otherwise... (even though it might be true :)
I must say your product quality/polish is nothing short of impressive.
ReplyDeleteWhat tool did you use for the image:
http://2.bp.blogspot.com/_z6qpykplUvI/TFrDxOeBk5I/AAAAAAAAA1E/0XLmUJTJRBk/s1600/taskcycle.png
Its clean/clear like your gui design.
Very impressive.
X-DDDDDD. Ok, ok, I'll uppercase Dick!! Promised! Thanks. :)
ReplyDelete@Andrew: thanks!! The image is plain Visio, nothing fancy I'm afraid... Just tweaking colors a little bit :-)
ReplyDeletePablo, that's a brilliant post! Short essay that can replace tons of texts about SCM.
ReplyDeleteThis one should be carved in marble :) :
FAQ: But, weren’t branches supposed to be evil?
ANSWER: Who told you that? I bet you found that on some Subversion guide, forum or manual, maybe even at some other SCM website, didn’t you?
True. So true :) I see a lot of people using wrong tools and saying that branching is evil.
Do you mind if I translate it in Russian?
Hi Aquary!
ReplyDeleteThanks for the kind words! :)
Yes, feel free to translate it to Russian, we'll love to see it! Send us the link!
Regards,
pablo
Pablo,
ReplyDeletethere's a typo in yours figures where you get the single line and a number of changesets.
Check figure 2 for example - there are 2 cset:10476 made by different users... Isn't that supposed to be 2 different csets like 10475 and 10476 ? I guess you can't do one cset using 2 users, can you?
@Acuary: thanks for the remark! I'll try to get it fixed ASAP. Question: do you need the visio files to translate to Russian?? Feel free to ask.
ReplyDeleteGuys: fixes are done:
ReplyDelete- I removed Dick and put Pat instead :)
- I fixed the issues on images (thanks Acuary!)
Hi Pablo... I become annoying ;) , but you've introduced cset 10474 without mentioning it; still cset 10475 is referred to as a cset with query changes which is supposed to be exactly 10474.
ReplyDeleteAnd - no, I'll just refer to your original figures in my translation :)
Hi Pablo, just FYI - I've translated this post, here it is:
ReplyDeletehttp://scm-notes.blogspot.com/2010/09/branch-per-task-workflow-explained.html
Now you have international publication ;)
Hi pablo,
ReplyDeleteread Aquary's russian translation and got some questions.
First - I think there is obvious difference between your approach and what "DVCS practitioners" offer.
Consider an example from here
http://nvie.com/posts/a-successful-git-branching-model/
$ git checkout develop
Switched to branch 'develop'
$ git merge --no-ff myfeature
Updating ea1b82a..05e9557
(Summary of changes)
$ git branch -d myfeature
Deleted branch myfeature (was 05e9557).
$ git push origin develop
Same thing I read in Linus Torvalds speech about git ( in russian ) - he dislikes to store working ( per- task) branches in central repository.
Conclusion - integrator role whose intent is to merge task-branches into trunk is very arguable, since "normally" task-branches exist on local copies only.
Did I get something wrong ?
Hi Maxim,
ReplyDeleteGlad to see you came to us through awesome's Acuary's translation! Great!
About your question/remark: well, I don't think there's a rule of thumb here, it's more a matter of choice, a matter of taste if you prefer.
The model you propose is: ok, you do your change on a branch, then merge it yourself, then you push the main branch.
When that happens, you'd have to:
a) Resolve any conflicts happened on the "master" while you were disconnected -> the burden of the integration goes back to you
b) You can potentially "destabilize" (not sure if that's a correct word! ;O) the remote master in case you break something. An alternative for this is a "pull request" as you'd do with GitHub, but then we end up with something "closer" to replicating the task branches although admitedly not exactly the same.
I normally recommend teams to keep all the task branches. Normally it is very good on commercial environments (companies) but I guess it doesn't make a lot of sense in the OSS world (and that's why Linus is saying that).
I've a huge respect (it can't be otherwise!) for Torvalds, he's a genius, so if he says he doesn't want to keep task branches, there must be a reason. But, I also understand Linux kernel development is not exactly the same scenario as the one companies face on a daily basis.
I totally agree with the approach of having "lieutenants" (integrators) doing the merges, because in a lot of scenarios it helps developers stay focused on what they do, and having someone "reviewing" the whole thing is pretty good.
So, you can also do (with Plastic) the same scenario of keeping task branches private. I'd always prefer to push them back to the main server so you've on single place with a "whole view" of what happened (sometimes correctly committed branches, done in steps, help understanding changes, even bisecting and so on), but that could be just a personal preference based on my own experience.
Thanks,
pablo
Excellent post.. very well explained!
ReplyDeleteExcellent post .. very well explained scenarios and a strong argument :)
ReplyDeleteJust a historical point: ClearCase has had branches since about 1990. I've been using them since 1996.
ReplyDeleteWe have evolved a method at my site for handling really tricky merges involving extensive changes that might be worth passing on. Projects like this are often out on development branches for long periods of time which makes the problem worse. In such a case we will have one person merge the main line and the development branch to an integration branch and then a second person merge the integration branch to main. That way all changes are inspected by two sets of eyes.
@Michael: sure, I'd love to hear about it. CC was our initial source of inspiration.
ReplyDelete